Training Museo de la Memoria
Acabo de recibir un dataset de grabaciones provenientes del Museo de la Memoria y los Derechos Humanos, situado en Santiago de Chile.
Con este dataset pretendo entrenar una serie de modelos los cuales puedan ser ocupados por participantes del Taller Materia y Memoria.
El dataset consiste en 120 grabaciones distribuídos en 120 archivos con un peso total de 63.43 GB.
A primera vista puedo ver las siguientes categorías entre el material:
- audio cartas
- grabaciones de programas de radio en el exterior
- grabaciones de conciertos en el exterior
- grabaciones historicas
- etc
Las características de grabación y fidelidad son muy distintas, por lo que algún tipo de preprocessing parece ser necesario como para poder tener un poco de homogeneidad dentro de la variedad del contenido. De esta manera, el proceso de entrenamiento y el o los modelos a aprender podrían ser un poco más homogéneos.
Por el momento, estoy creando las siguientes clases a partir de las grabaciones:
- CASA
- MUSICA
- HISTÓRICAS
He tomado cuidado de limpiar todos los inicios y finales de las grabaciones. La gran mayoría de las grabaciones posee un “click” bastante característico que probablemente fue originado al poner a grabar, parar o poner en pausa la máquina de caset utilizada para grabar. Si bien esta característica es común a cada caset, y podría ser un elemento distintivo de las grabaciones, opté por eliminarlo ya que pienso que el modelo aprenderá mucho de este elemento.
Opté por poner los muchos cantos que se dan en las calles (por ejemplo, la canción nacional o el pueblo unido jamás será vencido) en la capa de HISTÓRICAS, ya que no tienen las características acústicas de música.
TODOs:
- Decidir si los programas de radio, que de momento están en la pista MUSIC, también serán separados en VOICE y MUSIC como subcategoría de RADIO.
- Opté por dejarlos en una categoría llamada HISTÓRICAS.
- Hacer un workflow completo de preprocessing y export con lo que he hecho del dataset (20% de los datos)
- Exportar por layer -> Ableton export selected tracks. Los archivos generados no pueden ser más grandes de 2GB, por lo que hay que exportar por zonas.
- Remover los silencios con el data preprocessing.
- Implementé un variable thresholds en UDLS para eliminar audios bajo un determinado threshold. El valor default es -60 (dB). Valor de experimentos preliminares es -36.
resample --output ./OUT --stopthreshold -36
- Implementé un variable thresholds en UDLS para eliminar audios bajo un determinado threshold. El valor default es -60 (dB). Valor de experimentos preliminares es -36.
- Verificar lo generado: como hay un proceso dynamic audio normalizer, los audios salen con un volumen aparente bastante similar. quizás haya que eliminar los audios con mala calidad, o pre-procesarlos.
- Creo que es mejor nivelar los audios a mano y dejar que respiren musicalmente. Como el modelo responde también al nivel, esta característica puede ser codificada en el modelo y ser musicalmente expresiva.
Después de tres batchs completos de data, incluídos:
- Layering en tres capas (‘CASA’, ‘HISTORICAS’, y ‘MUSICA’)
-
Preprocessing (eliminación de silencio bajo -36dB y sin dynamic audio loudness normalization) Obtuve la siguiente cantidad de audio:
- 1-CASA: 3h18m25s
- 2-HISTORICAS: 7h57h53s
- 3-MUSICA: 3h45m07s
In regards to the RAVE model training, I set up 1M steps for the representational learning (VAE training) and 2M for the adversarial fine tuning. El tiempo aproximado de esta primera etapa de entrenamiento fue de casi seis días. Notar que hay dos modelos extras (WATERLAB) de entrenamientos de agua
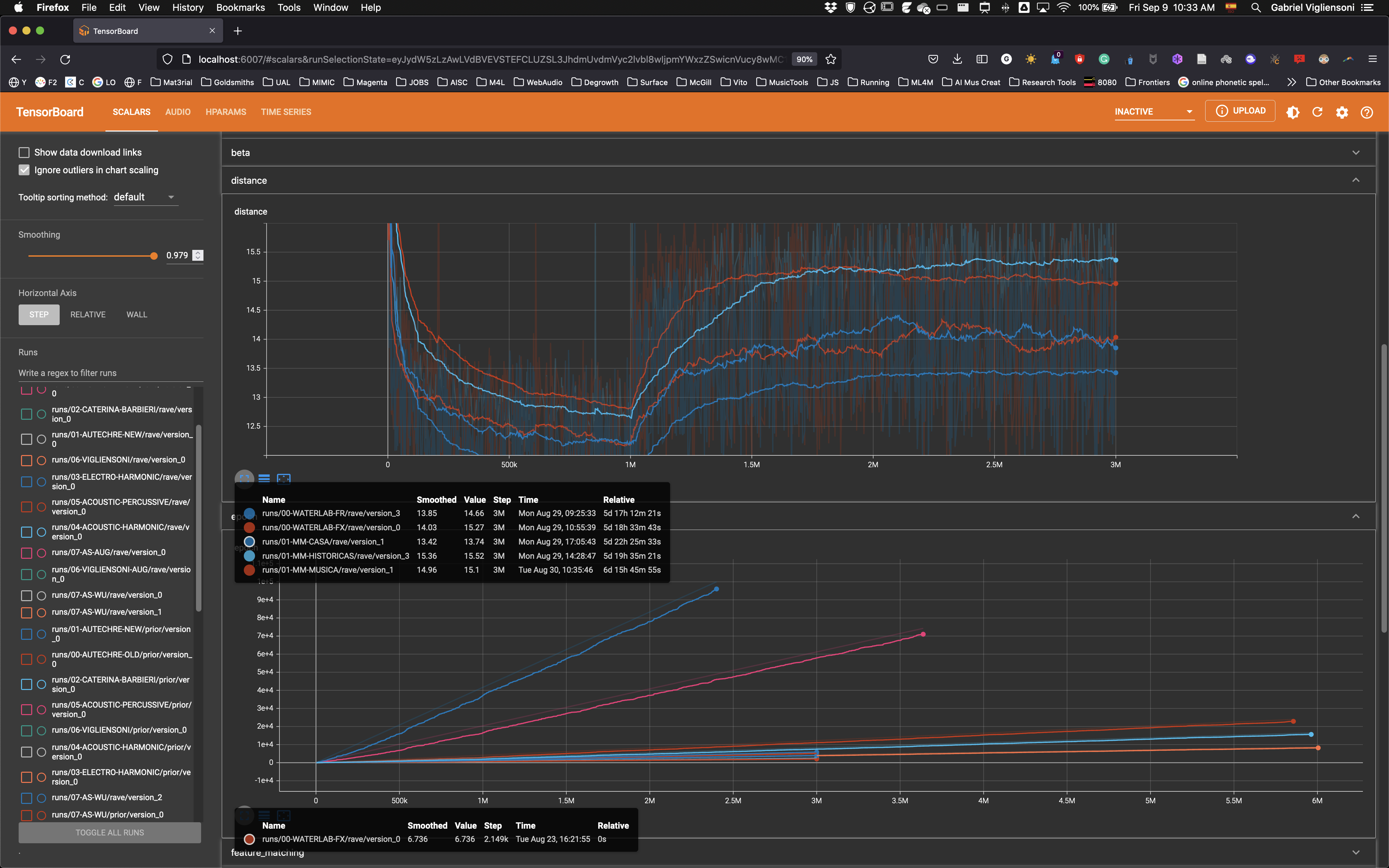
Los tiempos de entrenamiento del PRIOR (representación del espacio latente compactada) se muestran en la figura siguiente.
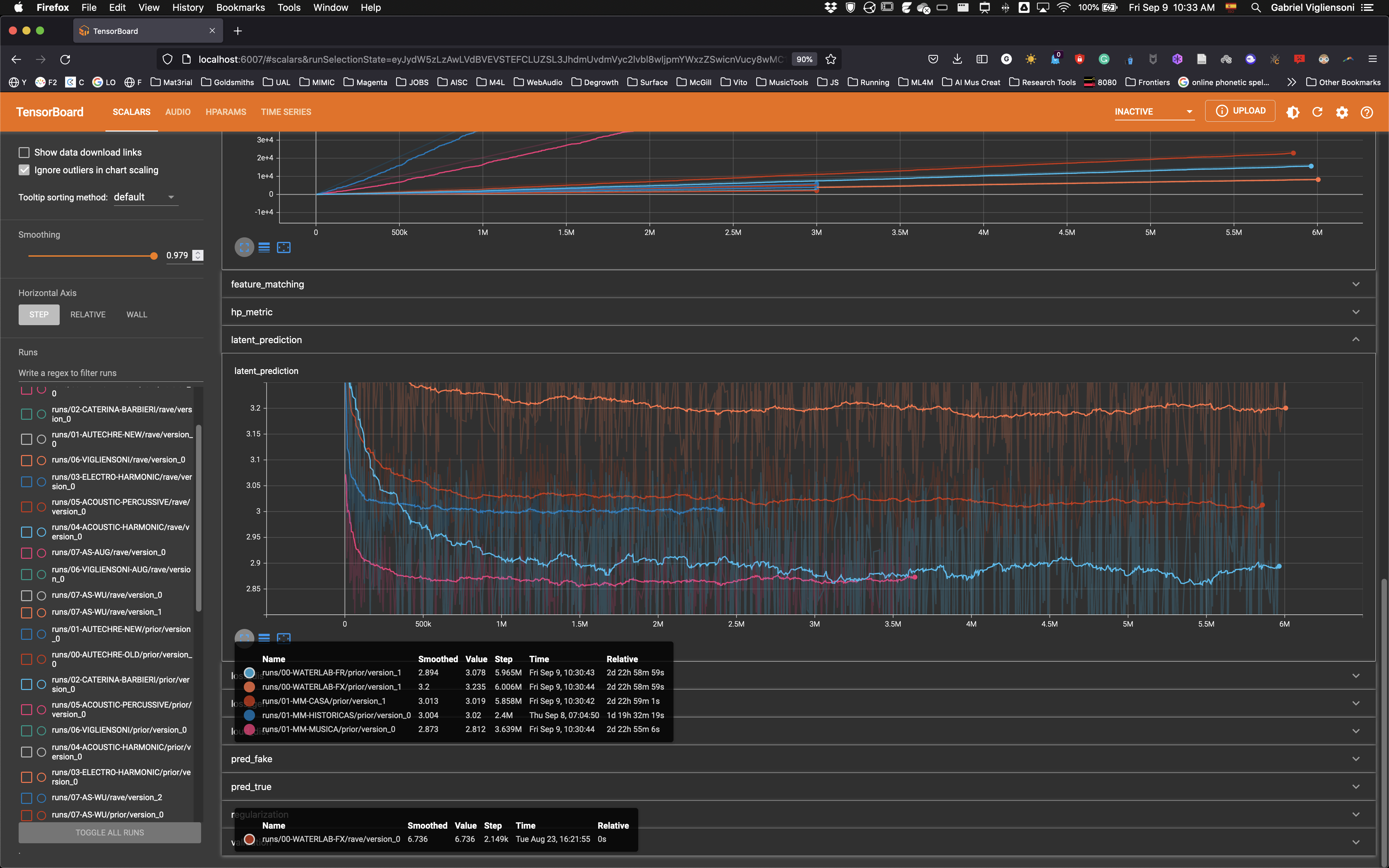
Se puede ver en varios casos, 6M steps tomó 3 días. Al mismo tiempo, se puede ver que la predicción del espacio latente no mejora demasiado después de 1 día. Para futuros entrenamientos, el tiempo de entrenamiento del PRIOR podría rebajarse a 1 día.
Primera audición de la generación en Tensorboard
Escuchando la generación desde TensorBoard, la primera percepción que tengo es que esta el timbre de los elementos (e.g., voces) pero se pierde el meaning. Cuando escucho el modelo de las músicas reconozco algunas de las canciones (e.g., “El pueblo unido”)
Subscribe to clastic music blog
Get the latest posts delivered right to your inbox