RAVE modelling
RAVE
- Training RAVE consists of two steps:
- RAVE training stages
- representational learning: VAE training
- adversarial fine tuning: encoder is fixed, and the decoder is trained with a GAN.
- PRIOR training
- latent representation compactness
- RAVE training stages
Training
Last week I finished the full training of a model. The dataset I used consists of a series of recordings and interviews collected by the Aventures Sonores collective. The dataset consists of 4.5 hours of speech recordings of:
- Poetry read by friends
- Conversations and historical recording s with First Nations from South America
- Audio documents about space and time
For this run, RAVE was trained with all default values: number of steps, fidelity, automatic dimensionality reduction, capacity, network architecture, etc.
The next figure shows the number of steps against epochs. It can be seen that the PRIOR training stopped at 100,000 epochs (default value) and took 1d 18h. RAVE training part (first two steps) stopped at 2M steps and took 4d 10h.
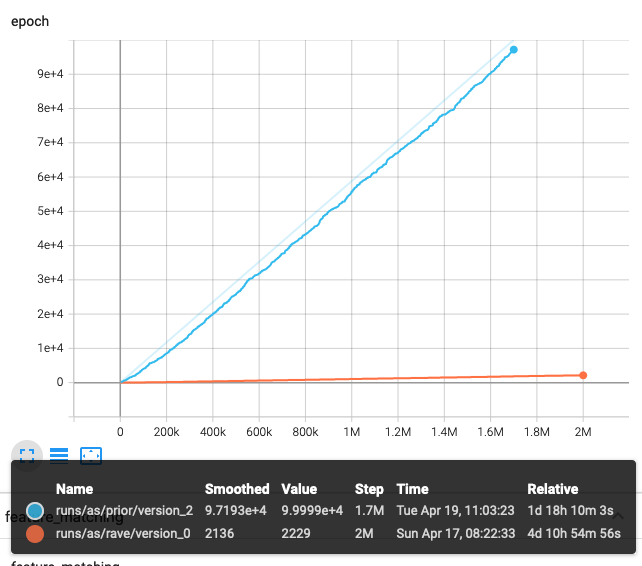
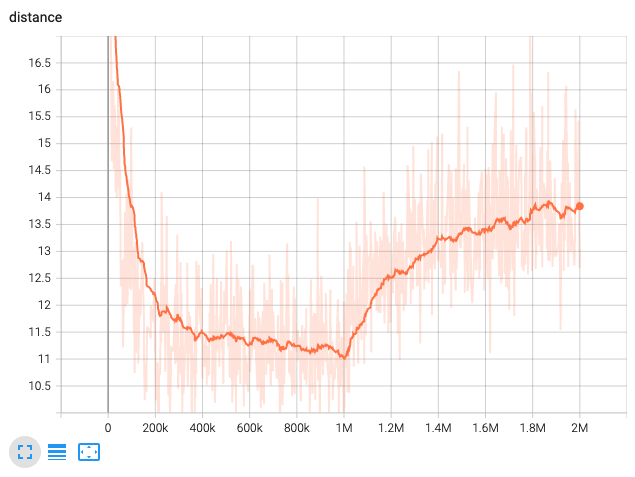
With the default values, RAVE is trained for 2M steps. The VAE part is trained for 1M steps and then the GAN stage starts automatically. The figure shows distance metric against step number.
Resulting model in musical applications
I tested the model with the nn~ MaxMSP object. I instantiated as a MaxMSP standalone and as a M4L patch inside Ableton. Both configurations allowed me to prime or excite the model decoder with actual audio recordings, while at the same time exploring the latent space of the decoder in real time.
Here are two audio examples of the first experimentations:
- The previous example has a few glitches due to computer processing. I used a better computer in the second run and adjusted the buffer of the
nn~object in order to reduce artifacts,
Training more models
I am now training seven new models consisting of the following corpora:
- 00-AUTECHRE-OLD (7.3h)
- 01-AUTECHRE-NEW (8h)
- 02-CATERINA-BARBIERI (5.9h)
- 03-ELECTRO-HARMONIC (21.8h)
- 04-ACOUSTIC-HARMONIC (32.7h)
- 05-ACOUSTIC-PERCUSSIVE (19.2h)
- 06-VIGLIENSONI (8.8h)
I run these training with the following changes:
- KL divergence is now fixed (not variable)
- Number of max steps was now set to 3M steps (MAX_STEPS = 3000000), to match the experiments of the paper. This max step number is not evenly distributed between VAE and GAN, but is 1M for VAE, and the rest for the GAN part. The VAE part of the training seems to be linked to a
warmupparameter in the repo (WARMUP = 1000000)
These models are currently being trained. As shown in the figure, the adversarial fine tuning started at 2M steps.
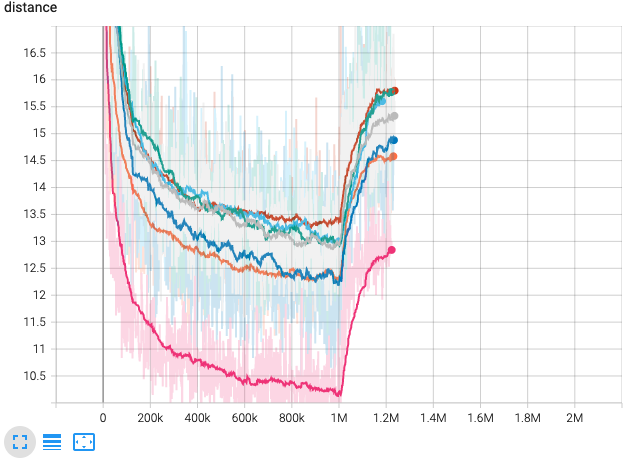
Data augmentation
RAVE provides a command line method for data augmentation
resample --sr 48000 --augment
resample --sr 48000 --input 06-VIGLIENSONI-AUG --output 06-VIGLIENSONI-AUG/out_48000 --augment
The method converts all audio file types to wav, converts them to a mono file, and resamples them to the desired sample rate.
It also comes with a method for measuring the duration of all audio files in a folder
duration
I applied data augmentation to the AS dataset, which consists mostly in spoken voice, and got the following results:
cd the-original-folder
duration
found 4 .wav files
total duration: 0h 12m 52s
cd the-augmented-folder
duration
Found 814 .wav files
total duration: 10h 31m 12s
I checked and listened to the results of the augmentation and the dynamics, sr, and filetype of the files were actually changed.
New jobs
- I submitted two new jobs with the augmented data. I made a change to the training parameters. The first one was to use the flag
--cropped-latent-size 16to see if the dimensionality of the resulting model is fixed instead of being computed automatically reduced. The target datasets for these new trainings are- 03-TR-07-AS-AUG
- 03-TR-06-VIGLIENSONI-AUG
- Following @moiseshorta’s advice I submitted another job with 5,000,000 warmup steps. It has the augmented data and default values for
latent size(128),max-kl(0.1) andmax_steps(3,000,000). To compare results, I’m also running it in the AS corpus.- 03-TR-07-AS-WU
- Although I specified
--warmup 5000000, the training stopped at 3M steps, and it didn’t go into the adversarial GAN part. The process stopped due to themax_steps 3000000specified in the code. - 03-TR-07-AS-WU-2
- Submitted now with
--warmup 5000000 --max-steps 8000000
The figure shows the epochs for the ten trainings:
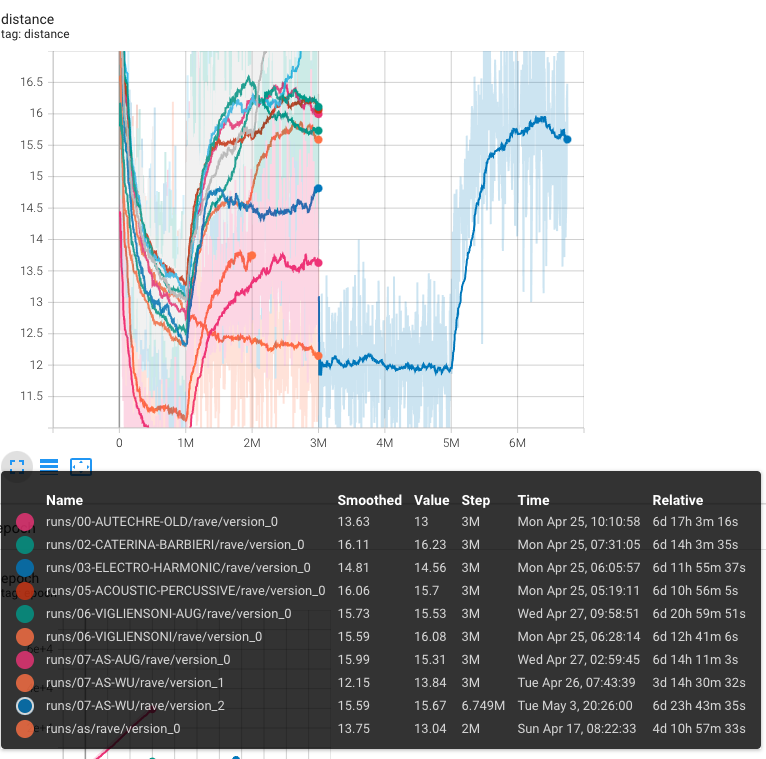
It can be seen that the default training setting ones had 1M steps for the first stage (VAE) and 2M steps for the 2nd stage (GAN). The last one (07-AS-WU) was trained for 5M steps (VAE) and 1.7M for the GAN
- Currently I’m also training the priors for the previous seven RAVE models, with default training times and without data augmentation.
- 04-TP-00-AUTECHRE-OLD
- 04-TP-01-AUTECHRE-NEW
- 04-TP-02-CATERINA-BARBIERI
- 04-TP-03-ELECTRO-HARMONIC
- 04-TP-04-ACOUSTIC-HARMONIC
- 04-TP-05-ACOUSTIC-PERCUSSIVE
- 04-TP-06-VIGLIENSONI
- 05-TP-06-VIGLIENSONI-AUG
- 05-TP-07-AS-AUG
- 05-TP-07-AS-WU
The /scratch folder in CC seems to be close to full. I just moved all audio files to ~/projects/rpp-ichiro/vigliens/9-MUZIK/
QUESTIONS
What are the following terms:
capacity : capability to learn some arbitrary function which can map the data to an index. there's capacity for the encoder and the decoder.
no-latency : related to PQMF (pseudo-quadrature mirror filters), sub-band coding for neural vocoders
cropped-latent-size : is this related to setting up a fixed latent space size instead of learning one?
FIX:
- Fix AS folder to leave it as all the other ones
PERFORMING WITH RAVE
I was invited to the first Planet Pillow night. I prepared a set with several of the models I trained and explored them in realtime using MaxMSP.
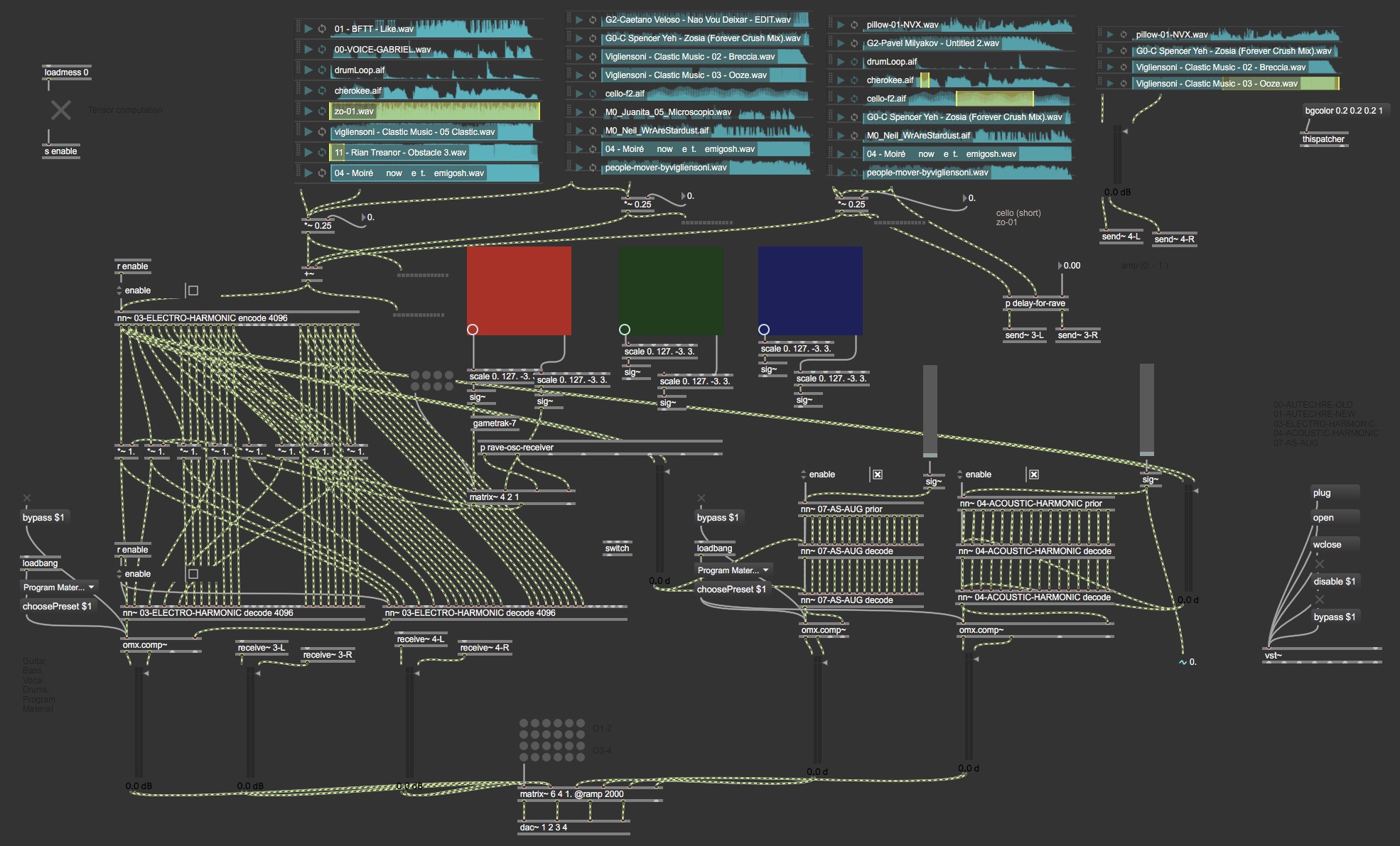
The models I used were:
- 03-ELECTRO-HARMONIC
- 07-AS-AUG
- 04-ACOUSTIC-HARMONIC
To achieve stereo output, I duplicated the decoder for all of them. All in all, the patch had the following neural networks instantiated:
- six decoders
- one encoder
- two priors
The audio outputs for all decoders were compressed with a ProgramMaterial preset to smooth the audio output.
The 07 and 04 models were use in an unconditional generation mode, and the only controls I with them were the temperature applied to the prior, and I also excited the decoder with the output of the 03 encoder.
At performance time, I excited the encoder of the 03-ELECTRO-HARMONIC model with signal coming from several audio files. In particular, at performance time it was enjoyable to play with:
cello-f2and controlling the looping selection until a very short loopzo-01made a very nice rhythmic looping structureObstacle 3by Rian Treanor was also nice, but I didn’t use it for the performance
I tried two different approaches to control the latent space:
-
One-to-one mapping: I controlled the bias in the latent space by moving the playback head in the red grid. The values of this head (i.e., [-3,3]) were multiplying the signal from the first two dimensions from the encoder latent space.
-
Many-to-many mapping: I trained a regressive model with Wekinator, a Gametrak controller, and the 04-ACOUSTIC-HARMONIC model. In this setup, six signals from the Gametrak were mapped to the first eight dimensions of the decoder.
The performance happened on May 20, 2022. It was a lovely evening of ambient, tones, and drone hosted by Michelle Azur and Emma.
Takeaways and considerations for next performances
Wekinator
- Wekinator is excellent to do the mappings between the performance and latent spaces. At training time, however, is hard to control the software while maintaining positions.
- Map some Wekinator parameters to external controllers so that it can be controlled without hands.
- Wekinator Input Helper is very useful to preprocess the input signals. For example, it has presets to compute first and second derivatives so that velocity and acceleration is computed
- In addition to position, use velocity and acceleration features when training models
Stereo signals
- Stereo field was greatly increased by duplicating the decoders and exciting them with different signals. I’m actually duplicating the processing load of the computer to achieve this.
- Decide which of the decoders have to be duplicated.
Model training and expressiveness
- It doesn’t make any sense to train gestures latent space with one model and then use another model. Some mappings may work, but it is very likely that you will find annoying zones in the space.
- I will create a few mapping models with clear labels for tracker and model.
Computer performance
- The performance had many sound glitches—the computer was struggling.
- Determine if the previous changes decrease the load of the computer. Otherwise, use a more cautious approach and use fewer networks (i.e., 5?)
Data augmentation
- There’s no need to augment the data to 48KHz, default
resamplevalue is 44.1KHz --augmentflag compresses and pumps the audio too much. This is especially bad for zones with soft background noise. In informal experiments, soft signals were pumped 34dB, making barely noticeable background noise very present. See https://github.com/caillonantoine/UDLS/issues/2
Alliance
I’m having issues with space
/scratch (user me) 3633M/20T 110k/1000k /project (group me) 19M/2048k 2/1025 /project (group rpp-xxx) 203G/10T 81k/500k /project (group rpp-yyy) 52k/2048k 8/1025 /project (group def-xxx) 999G/1000G 772k/5000k
I’m moving my data to /project/rpp-xxx/me.
So far, I have
9-MUZIK
00-WATERLAB
01-MUSEO-MEMORIA
To run and tunnel Tensorboard
- Run TB in the remote computer, write down the server (e.g., cdr2597)
- In local machine, create a tunnel:
- ssh -N -f -L localhost:6006:cdr2597:6006 me@server.computecanada.ca
- In local machine, go to the browser and point to port 6006 (if that’s the one chosen)
- More info
Additional info
1 epoch = the model has "seen" the entirely of the dataset once
there are dataset_length / batch_size steps per epoch. One must take into consideration the split between validation and training sets to get the exact numbers.
Resuming training from checkpoint
Hi ! Last is the last checkpoint saved, v1 means it is an intra epoch checkpoint, best is the checkpoint with the best validation loss ! Usually I recommend using the last checkpoint as the validation loss only is valid for the first phase
Dataset size
Something like ~2hours would make a better fit :)
I notice that the cli_helper.py script, and more generally the configuration for a training job, offers two options for the warmup step value:
small/default -> 1000000
large -> 3000000
RAVE will chop up your audio files into chunks of size N_SIGNAL during training. The default value for N_SIGNAL is 65536, so about 1.36 seconds.
Training tips for complex datasets
Just wanted to share some insights into training RAVE with complex datasets (full songs, heterogeneous sounds).
One solution I've come across having a good convergence on models is:
- extending the latent size parameter to a full 128.
Also, which is what I think had a greater impact, is to
- extend the Phase 1 training or warmup to about 5 million steps before switching to Phase 2.
Obviously, more data will have better results, but so far I've found that the more 'detailed' features in my dataset, namely melodies, textures of individual mid-to-high freq. range instruments seem to start converging better beyond the suggested warmup phase of 1 million steps, as the loss keeps consistently going down.
If you want a "bigger" RAVE model, I suggest that you pass the following argument while training --ratios "[4, 4, 2, 2, 2]" ! It will allow RAVE to capture much complex structure, at the expense of a higher computational load during inference ! I'm about to add some additional configurations to the training script ("small", "regular" and "large") !
Order
=================================================
TEST: TRAINING INSTRUCTIONS
=================================================
TRAIN RAVE
----------
Train rave (both training stages are included)
python train_rave.py --name test --wav ./wavs --preprocessed /tmp/test/rave --capacity 4294967296 --no-latency true --cropped-latent-size 48
You can follow the training using tensorboard
tensorboard --logdir . --bind_all
Once the training has reached a satisfactory state, kill it (ctrl + C)
TRAIN PRIOR
-----------
Export the latent space trained on test.
python export_rave.py --run runs/test/rave --cached false --name test
Train the prior model.
python train_prior.py --pretrained-vae rave_test.ts --preprocessed /tmp/test/prior --wav ./wavs --name test
Once the training has reached a satisfactory state, kill it (ctrl + C)
=================================================
EXPORT TO MAX MSP
=================================================
In order to use both **rave** and the **prior** model inside max/msp, we have to export them using **cached convolutions**.
python export_rave.py --run runs/test/rave --cached true --name test_rt
python export_prior.py --run runs/test/prior --name test_rt
python combine_models.py --prior prior_test_rt.ts --rave rave_test_rt.ts --name test
Subscribe to clastic music blog
Get the latest posts delivered right to your inbox